同程旅行大数据集群在Kubernetes上的服务化实践 数据处理服务篇
随着业务规模的快速增长和技术的演进,传统的大数据集群管理模式在弹性伸缩、资源利用率和运维复杂度方面面临巨大挑战。同程旅行作为在线旅行行业的领先者,积极探索并实践将大数据处理服务迁移至Kubernetes平台,以实现更高效、更灵活、更稳定的数据处理能力。本文将聚焦于数据处理服务在Kubernetes上的服务化实践,分享其中的关键架构、技术选型与实施经验。
一、背景与驱动力
同程旅行原有的Hadoop、Spark、Flink等大数据组件运行在物理机或虚拟机构成的静态集群上。这种架构虽然成熟稳定,但也存在资源隔离性差、弹性不足、多租户管理复杂、资源利用率不均衡等问题。Kubernetes作为容器编排的事实标准,其强大的声明式API、自动化的部署与伸缩能力、精细化的资源管理以及活跃的社区生态,为解决这些问题提供了理想的平台。
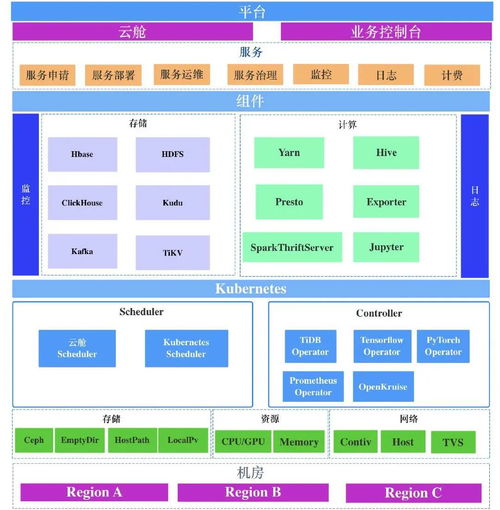
二、核心架构设计
数据处理服务的Kubernetes化并非简单的容器化部署,而是一个系统性的服务化重构过程。核心设计原则包括:
- 计算与存储分离:将计算层(Spark/Flink作业执行器)与存储层(HDFS/S3)解耦。计算任务以无状态Pod形式在Kubernetes上弹性运行,通过远程接口访问统一的持久化存储。这大幅提升了计算资源的独立伸缩能力。
- Operator模式驱动:为Spark、Flink等复杂有状态应用开发或采用成熟的Kubernetes Operator(如Spark-on-K8s Operator, Flink Kubernetes Operator)。Operator将领域知识编码为Kubernetes的扩展API和控制器,实现了大数据作业的声明式管理、生命周期自动化(如提交、监控、重启、伸缩)和与Kubernetes生态的无缝集成。
- 多租户与资源隔离:利用Kubernetes的Namespace、ResourceQuota、LimitRange等机制,为不同的业务线或团队划分资源配额和隔离边界。结合网络策略(NetworkPolicy)和基于RBAC的权限控制,构建安全的多租户数据处理环境。
- 统一的服务发现与访问:通过Kubernetes Service和Ingress,为数据处理服务(如Spark History Server、Flink JobManager Web UI、自研的数据服务API)提供稳定、统一的内部和外部访问入口,简化了服务间调用和管理。
三、关键技术实践
- 容器镜像与依赖管理:为Spark、Flink等构建包含运行时依赖、优化配置及公司内部组件的标准基础镜像。利用镜像仓库进行版本管理,并通过Init Container或Sidecar模式动态注入作业特定的JAR包、配置文件,实现镜像的通用性与作业定制化的平衡。
- 作业提交与调度优化:将传统的YARN作业提交方式迁移为直接向Kubernetes API Server提交(通过
spark-submit或Flink CLI),或通过Operator/自研调度平台提交。利用Kubernetes的调度器,结合节点亲和性、污点与容忍等策略,将计算密集型作业调度到特定硬件节点(如GPU机器),优化整体集群性能。
- 弹性伸缩与成本控制:基于Custom Metrics API和HPA(Horizontal Pod Autoscaler),实现数据处理作业执行器(如Spark Executor、Flink TaskManager)在作业运行期间的动态横向伸缩,快速响应数据处理负载变化。结合Cluster Autoscaler,在资源不足时自动扩容Kubernetes节点,在负载低谷时缩容,有效控制云计算成本。
- 可观测性增强:集成Prometheus、Grafana、ELK等云原生监控日志栈。为大数据作业Pod注入Sidecar容器,自动采集标准输出日志、Metrics指标(如JVM状态、作业进度)并上报至中心平台。构建统一的仪表盘,实现从Kubernetes基础设施层到大数据应用层的端到端监控与告警。
- 存储与网络适配:针对大数据场景的高IO需求,采用Local PV、高性能云盘或CSI插件对接企业存储方案,为有临时存储需求的作业提供高效本地缓存。网络方面,选用合适的CNI插件(如Calico、Cilium),确保Pod间大数据量传输的性能与稳定性。
四、挑战与应对
实践过程中也遇到诸多挑战:
- 状态管理与数据本地性:无状态化设计削弱了HDFS数据本地性优势。通过优化网络带宽、使用远程存储加速技术(如Alluxio缓存层)和智能调度策略来弥补性能损耗。
- 复杂作业的稳定性:长周期、有状态的流处理作业(如Flink Job)在Pod重启或节点故障时的恢复是一大挑战。通过Operator实现的精确状态管理(保存点/检查点)、高可用配置以及与持久化存储的深度集成来保障作业的健壮性。
- 运维习惯与工具链迁移:推动数据开发与运维团队适应Kubernetes的运维模式,并提供兼容旧有使用习惯的CLI工具、Web控制台和API,降低迁移门槛。
五、收益与展望
通过将大数据处理服务迁移至Kubernetes,同程旅行获得了显著的收益:资源利用率提升超过30%,集群部署与弹性伸缩效率大幅提高,运维自动化水平增强,并为混合云/多云部署奠定了坚实基础。我们将进一步探索Serverless大数据处理(如Kubernetes Native的批处理框架)、AI与大数据工作流的统一调度、以及基于服务网格(Service Mesh)的更细粒度流量治理,持续推动数据处理平台向更智能、更高效、更云原生的方向演进。
同程旅行的实践表明,Kubernetes不仅适用于微服务,也为大规模、多样化的数据处理工作负载提供了强大的现代化基础设施。这一转型为业务快速创新提供了坚实的技术支撑。
如若转载,请注明出处:http://www.smnxr.com/product/18.html
更新时间:2026-06-18 05:52:22