哔哩哔哩数据服务中台建设实践 构建高效可靠的数据处理服务
随着哔哩哔哩(B站)业务规模的快速扩张和用户数据的爆炸式增长,构建一个统一、高效、可靠的数据服务中台已成为支撑其业务创新和精细化运营的关键基础设施。本文将重点探讨哔哩哔哩在数据处理服务方面的中台建设实践,揭示其如何通过技术架构优化与服务化改造,应对海量数据处理的挑战,并为全公司提供稳定、敏捷的数据支撑。
一、背景与挑战
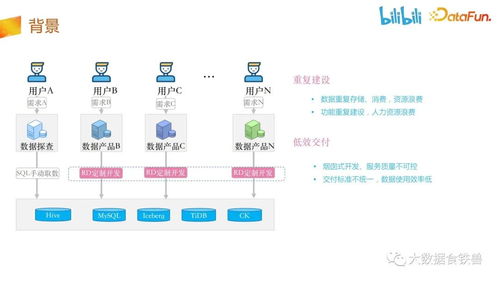
哔哩哔哩作为国内领先的年轻人文化社区,每日产生数以亿计的用户行为日志、视频播放数据、互动评论及交易信息。传统的数据处理模式存在诸多痛点:数据孤岛现象严重,各部门数据口径不一;数据处理链路冗长,从采集到分析耗时数天;资源利用率低下,计算任务调度不均;数据质量参差不齐,影响决策准确性。这些挑战迫使B站必须从全局视角重构其数据处理体系,建设一个能够统一管理、高效运行的数据服务中台。
二、核心架构设计
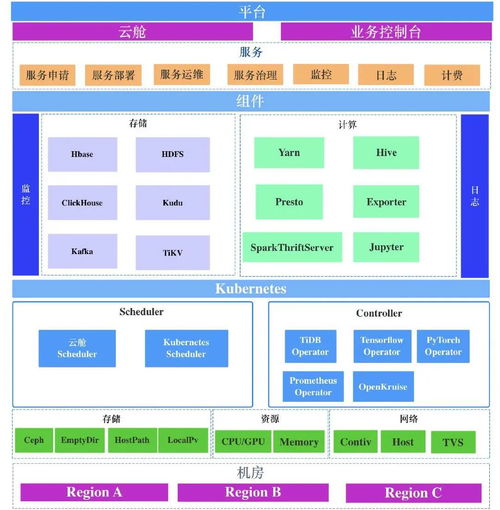
哔哩哔哩的数据处理服务中台采用分层、模块化的架构设计,主要包含以下核心组件:
- 统一数据采集与接入层: 通过自研的Agent与SDK,实现对全站多源数据(如客户端埋点、服务端日志、数据库Binlog、第三方数据)的实时与批量采集。该层采用高可用分布式设计,确保数据不丢不重,并提供灵活的数据格式解析与初步过滤能力。
- 流批一体的计算引擎层: 基于Apache Flink和Spark构建了统一的流批处理引擎。对于实时性要求高的场景(如推荐系统实时特征、监控告警),采用Flink进行毫秒级流处理;对于大规模历史数据分析、报表生成等场景,则利用Spark进行高效的批量计算。通过统一的计算框架,减少了开发与维护成本。
- 中心化的数据存储与管理层: 构建了以HDFS、HBase、ClickHouse、Redis等为核心的多模数据湖/仓体系。通过元数据管理系统,对所有数据资产进行集中注册、分类与血缘追踪,实现数据“可发现、可理解、可信任”。引入数据生命周期管理策略,自动对冷热数据进行分级存储与归档,优化存储成本。
- 数据服务化与API网关: 将处理后的数据(如用户画像、视频热度指标、业务统计报表)封装成标准的API服务,通过统一的API网关对外暴露。网关负责流量控制、权限认证、监控告警等,确保数据服务的安全、稳定与高可用。业务方无需关心底层数据来源与处理逻辑,通过简单调用即可获取所需数据。
- 运维监控与数据质量体系: 建立了覆盖全链路的数据运维监控平台,对数据采集延迟、计算任务健康度、存储资源使用率等进行实时监控与智能告警。通过定义数据质量规则(如完整性、一致性、准确性校验),并在关键节点进行自动化检测,形成了“事前预防、事中监控、事后追溯”的数据质量保障闭环。
三、关键实践与成效
- 任务调度与资源优化: 自研了智能任务调度系统,根据任务优先级、数据依赖关系以及集群资源状况,进行动态调度与资源分配,将整体集群资源利用率提升了40%以上,关键任务准时完成率超过99.9%。
- 数据模型标准化: 推动公司级统一数据模型(如用户、视频、订单等主题域模型)的建设,确保了跨部门数据口径的一致,大幅减少了因数据理解歧义导致的沟通与开发成本。
- 实时数据能力提升: 通过流处理引擎的深度优化,将核心业务指标(如DAU、视频实时播放量)的产出延迟从小时级降低到秒级,有力支撑了实时推荐、运营大屏、风控预警等对时效性要求极高的业务场景。
- 成本控制与效率提升: 通过存储分层、计算任务优化、闲置资源回收等系列措施,在数据量年增长数倍的情况下,实现了单位数据处理成本的显著下降。数据服务的标准化使业务方获取数据的平均周期从数周缩短到数天甚至实时,研发效率倍增。
四、未来展望
哔哩哔哩的数据处理服务中台建设已取得阶段性成果,但面对AI驱动的智能化趋势和持续增长的数据规模,未来还将朝以下方向演进:深化数据湖仓一体架构,探索更极致的实时与交互式分析能力;加强数据安全与隐私计算技术,在数据价值挖掘与用户隐私保护间取得平衡;推动数据与AI平台融合,提供从数据预处理、模型训练到在线服务的端到端AI能力支持,为B站业务的持续创新注入更强大的数据动力。
###
哔哩哔哩的数据处理服务中台建设,是一次以业务价值为导向、以技术架构为支撑的系统性工程。它不仅解决了当下海量数据处理的效率与质量难题,更通过服务化、标准化的方式,将数据能力沉淀为易于取用的企业级资产,为B站在复杂多变的互联网竞争中构建了坚实的数据基石。其实践经验,也为业界同类大规模数据平台的建设提供了有价值的参考。
如若转载,请注明出处:http://www.smnxr.com/product/3.html
更新时间:2026-06-18 11:20:16