从小作坊到数据工厂 小白也能看懂的大型互联网架构演进之旅
想象一下,你开了一家社区小卖部。起初,你一个人就能搞定:进货、记账、收银、理货全包。但随着生意越来越好,顾客越来越多,你开始手忙脚乱。这时候,你需要分工合作——请个收银员、雇个理货员,甚至用上电脑记账。
互联网公司的数据处理服务,其演进过程与此惊人相似。今天,我们就来聊聊这段从“一人包办”到“精密工厂”的演进故事,保证小白也能看懂。
第一阶段:单机时代 - “个人英雄主义”
就像最初的小卖部,早期的网站应用非常简单。一个应用服务器(比如一台物理机或虚拟机)就包揽了所有工作:
- 接收用户请求:用户点击网页或APP。
- 处理业务逻辑:计算、判断、执行操作。
- 读写数据库:把用户数据存进去,或查出来。
- 返回结果:把网页或数据展示给用户。
这时的“数据处理服务”就是应用服务器自己,直接连接一个数据库(如MySQL)。所有数据都堆在一个库里,简单直接,但风险巨大——服务器一宕机,整个服务就挂了;数据库一张表坏了,数据可能全丢。这就像你的记账本被水泡了,所有账目一团糟。
第二阶段:应用与数据分离 - “初次分工”
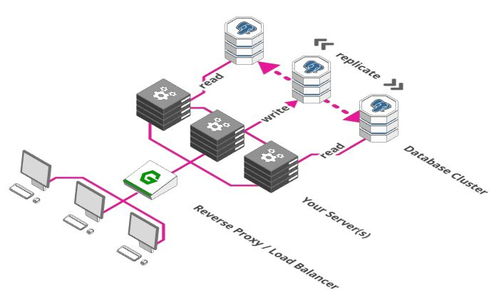
生意做大了,你发现记账和卖货互相干扰。于是,你把“收银台”(应用服务器)和“仓库/账房”(数据库服务器)分开,用网线连接。
在技术层面,这就是应用层与数据层的分离。
- 应用服务器集群:多台服务器专门负责处理业务逻辑和响应请求。一台挂了,其他的能顶上,保证了服务不中断(高可用)。
- 数据库服务器:独立出来,专门负责数据的持久化存储和查询。
但问题又来了:所有顾客(用户请求)都问同一个账房先生(数据库),他很快就不堪重负,查询速度变慢,成为整个系统的瓶颈。
第三阶段:引入缓存与读写分离 - “设立快速通道和专员”
为了缓解数据库压力,架构师引入了两大法宝:
- 缓存(Cache):想象你在收银台旁边放了个小本子,专门记录“今天卖得最好的10种商品及其价格”。顾客来问这些热门商品,你无需每次都跑去仓库查账,看一眼小本子就能立刻回答,速度极快。这就是缓存(如Redis、Memcached),将高频访问的“热数据”放在访问速度极快的内存中,极大减轻数据库压力。
- 数据库读写分离:账房先生忙不过来?那就给他配个助手!架构上,我们设置一个主数据库(Master) 负责“写操作”(存钱、记账),再设置几个从数据库(Slave) 负责“读操作”(查账)。主数据库的数据会同步到从数据库。这样,大部分查询请求都由多个从库分担,性能大幅提升。
此时,“数据处理服务”开始细化,不再是数据库单打独斗,而是由“数据库+缓存”共同承担。
第四阶段:分库分表与引入NoSQL - “建立专业分仓和新型仓库”
当业务爆炸式增长,成为淘宝、微信这样的巨无霸时,单一数据库再怎么做读写分离也撑不住了。数据量太大(数十亿条记录),查询太复杂。
解决方案是“化整为零”:
- 分库分表:把原本一个庞大的数据库,按照某种规则(比如用户ID尾号、地区)拆分成多个小的数据库(分库),每个小库里的表再进一步拆分(分表)。这就像把你的巨型仓库,按商品类别(家电仓、服装仓、食品仓)或地区(华北仓、华南仓)拆分成多个专业、易管理的中型仓库。
- 引入NoSQL数据库:关系型数据库(如MySQL)擅长处理严谨的、需要事务保证的数据(比如银行转账)。但对于海量、结构灵活的数据(比如用户的社交动态、商品图片链接),就显得力不从心。于是,像MongoDB(文档型)、HBase(列式)、Elasticsearch(搜索) 等NoSQL数据库被引入,它们为特定类型的数据处理而生,性能更高。
至此,“数据处理服务”变成了一个由多种数据库、缓存组成的混合数据层,每种组件各司其职。
第五阶段:大数据平台与服务体系化 - “建设自动化数据工厂”
当数据真正成为“石油”,公司不仅需要存储和查询数据,更需要加工、分析、挖掘数据价值。这就进入了大数据时代。
数据处理服务演进为庞大、复杂的 “数据平台”:
- 数据仓库与OLAP:建立专门的数据仓库,将各业务线的数据清洗、整合后存入。使用ClickHouse、Doris等OLAP数据库,支持超大规模数据的快速分析报表,帮助老板做决策。
- 实时计算:用户刚点击一个商品,推荐系统瞬间就能推荐相似商品。这背后是Flink、Spark Streaming等实时计算引擎,对数据流进行毫秒级处理。
- 数据湖:存储公司所有的原始数据(包括结构化和非结构化),像一个巨大的原始湖泊,供后续各种挖掘使用。
- 统一数据服务层:面对前台成百上千个应用,数据平台不再允许它们直接访问底层复杂的数据库。而是抽象出一层统一的数据服务接口。应用只需调用简单的API,就能获取加工好的、安全的数据。这就像工厂建立了统一的“销售接待处”,客户不用再深入车间。
演进的驱动力与核心思想
回顾整个历程,架构演进的核心驱动力始终是:不断增长的数据量、并发访问量以及业务复杂度。而其核心思想万变不离其宗:
- 拆分与解耦:把大系统拆成小部件,降低复杂性,提高可维护性。
- 分工与专用:让专业组件处理专业问题,追求极致效率。
- 冗余与备份:没有单点故障,任何一环坏了都有备份,保证系统整体可用。
- 自动化与平台化:从手动运维到智能调度,从散装工具到统一平台。
所以,下次当你打开一个APP,瞬间加载出个性化内容时,你可以想象,这背后是一整套精密、协同的“数据工厂”在为你高速运转。从单机到分布式,从数据库到数据中台,这场演进之旅,本质就是一部互联网业务不断攀登数据高峰的奋斗史。
如若转载,请注明出处:http://www.smnxr.com/product/7.html
更新时间:2026-06-18 05:37:46